[CNN] (1) Convolutional Neural Networks 개요
CNN 카테고리 포스팅을 시작하기에 앞서, 전체적인 개요를 간략하게 정리했습니다.
아래 목차에 해당하는 각 항목들은 추후 별도의 글에서 상세히 다룰 예정입니다.
CNN 시리즈
- Convolutional Neural Networks 개요
- CNN의 역사와 발전 과정, 주요 모델들
- 컨볼루션 레이어(Convolutional Layer)
- 패딩(Padding)과 스트라이드(Stride)
- 풀링 레이어(Pooling Layer)
- 정규화 레이어(Normalization Layer)
1. 소개: CNN이란 무엇인가?
CNN(Convolutional Neural Network)은 이미지 인식, 객체 탐지 등 시각적 데이터(Visual Data) 처리에 특화된 딥러닝(Deep Learning) 모델입니다. 전통적인 FCN(Fully-Connected Neural Network)과 달리, CNN은 컨볼루션 연산(Convolution Operation)을 통해 이미지의 지역적(local) 특징을 자동으로 추출합니다. 이렇게 추출된 특징은 레이어을 거칠수록 더욱 복잡하고 추상화된 형태가 되며, 별도의 특징 공학(Feature Engineering) 없이도 높은 인식 정확도를 달성할 수 있습니다.
CNN의 기본 개념은 인간의 시각 피질(Visual Cortex) 구조에서 영감을 받아 제안되었으며, 오늘날 컴퓨터 비전 분야의 핵심 알고리즘으로 자리 잡았습니다1. 예컨대, CNN 기반 분류기는 초기 레이어에서는 엣지(edge)나 모서리 같은 저수준(Low-Level) 특징을 감지하고, 깊은 레이어으로 갈수록 물체 전체 형태나 복잡한 패턴처럼 고수준(High-Level) 특징을 추출합니다. 이러한 레이어적 특징 학습(Hierarchical Feature Learning) 덕분에 CNN은 위치 이동이나 왜곡에도 비교적 견고한(invariant) 성능을 보입니다.
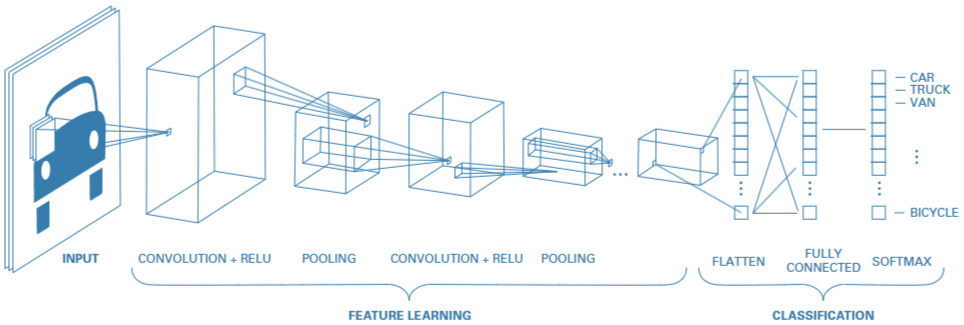 A simple CNN for classifying images2
A simple CNN for classifying images2
2. CNN의 역사
2.1. 초기 구상 (1960년대 ~ 1980년대)
CNN의 아이디어는 Hubel과 Wiesel의 연구에서 비롯되었습니다. 고양이의 시각 피질(Visual Cortex)에 있는 뉴런들은 특정 모서리(edge)나 윤곽(contour)에 반응한다는 실험 결과가 지역적 특징 추출 개념에 영향을 주었습니다. 1980년대 후반 Fukushima가 제안한 Neocognitron은 국소 연결과 레이어적 구조를 갖춘, 현재의 CNN과 유사한 초기 모델이었습니다.
2.2. LeCun의 공헌 (1990년대)
오차역전파(Backpropagation) 알고리즘이 발전하면서, Yann LeCun은 손글씨 숫자 인식에 특화된 LeNet-5 모델을 발표했습니다1. LeNet-5는 컨볼루션 레이어(Convolutional Layer)과 풀링 레이어(Pooling Layer)을 반복 적용한 뒤, 마지막에 완전연결 레이어(Fully-Connected Layer)을 이용해 분류하는 구조로, 당시 MNIST 데이터셋에서 매우 우수한 성능을 보였습니다.
2.3. 딥러닝의 부활 (2010년대)
2012년 AlexNet이 ImageNet 대회에서 압도적인 성능 차이를 보이며 CNN의 저력을 다시금 증명했습니다3. 이후 VGGNet4, GoogLeNet(Inception)5, ResNet6 등 다양한 심층 CNN 아키텍처들이 발표됨으로써, CNN은 컴퓨터 비전 분야의 대표 모델로 자리 잡았습니다.
3. CNN의 주요 구성 요소
CNN은 일반적으로 컨볼루션 레이어(Convolutional Layer) → 활성화 함수(Activation Function) → 풀링 레이어(Pooling Layer)를 여러 차례 반복한 후, 마지막에 완전연결 레이어(Fully-Connected Layer)으로 최종 예측을 수행합니다.
3.1. 컨볼루션 레이어 (Convolutional Layer)
컨볼루션 레이어은 학습 가능한 필터(Filter) 또는 커널(Kernel)을 사용해 입력 이미지에 컨볼루션 연산을 적용합니다. 예를 들어, 필터 크기가 \(H_f \times W_f\)라면, 출력 Feature Map의 한 픽셀 \(y(i,j)\)는 다음과 같이 계산됩니다:
\[y(i,j) = \sum_{u=0}^{H_f-1} \sum_{v=0}^{W_f-1} x(i+u,\, j+v) \cdot w(u,v) + b\]- \(x(i+u, j+v)\): 입력 이미지의 해당 영역(패치, patch) 픽셀 값
- \(w(u,v)\): 필터 가중치(Weight)
- \(b\): 편향(Bias)
이렇게 국소 영역(Local Receptive Field)에만 연결되고, 가중치 공유(Weight Sharing)를 통해 파라미터 수를 크게 줄일 수 있습니다.
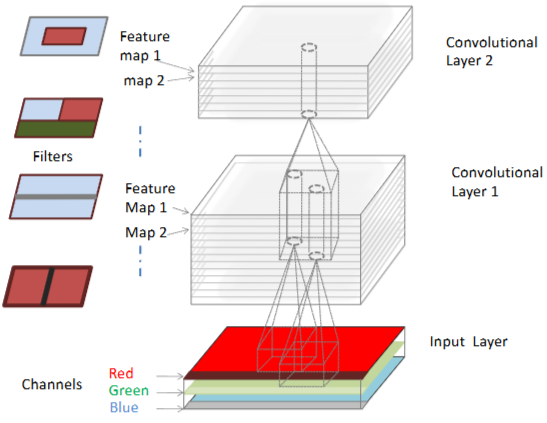 llustration of a CNN with 2 convolutional layers2
llustration of a CNN with 2 convolutional layers2
3.2. 활성화 함수 (Activation Function)
컨볼루션 레이어의 출력을 비선형으로 변환하기 위해 ReLU(Rectified Linear Unit)와 같은 활성화 함수가 주로 사용됩니다:
\[\mathrm{ReLU}(x) = \max(0, x).\]ReLU는 계산이 간단하며, 기울기 소실(Vanishing Gradient) 문제를 어느 정도 완화해 학습 속도를 높이는 장점이 있습니다.
3.3. 풀링 레이어 (Pooling Layer)
풀링(Pooling)은 컨볼루션 레이어에서 만들어진 Feature Map을 다운샘플링(Downsampling)하여 공간적 크기를 축소하고, 위치 변화에 대한 불변성(Invariance)을 높이는 역할을 합니다. 대표적으로 맥스 풀링(Max Pooling)이 있으며, 일정 영역 내에서 최댓값을 취하는 방식으로 특징을 압축합니다.
3.4. 완전연결 레이어 (Fully-Connected Layer)
여러 컨볼루션과 풀링 레이어을 통과해 추출된 Feature Map을 1차원 벡터로 펼친 후, 하나 이상의 완전연결 레이어을 거쳐 최종 분류(Classification) 또는 회귀(Regression)를 수행합니다. 분류 문제에서는 마지막에 소프트맥스(Softmax) 함수를 적용해 각 클래스의 확률을 출력합니다.
4. 다양한 CNN 아키텍처와
4.1. AlexNet (2012)
- 특징: 5개의 컨볼루션 레이어과 3개의 완전연결 레이어, ReLU 활성화, 드롭아웃(Dropout), GPU(Graphics Processing Unit) 병렬처리
- 기여: ImageNet 대회에서 기존 오류율을 큰 폭으로 낮추며 딥러닝 붐을 일으킨 모델3
4.2. VGGNet (2014)
- 특징: 16~19층의 심층 구조로, 모든 컨볼루션을 3×3 필터로 통일
- 기여: 네트워크를 깊게 쌓는 방식이 성능 향상에 효과적임을 체계적으로 입증4
4.3. GoogLeNet(Inception) (2014)
- 특징: Inception 모듈을 통해 다양한 크기의 필터를 병렬로 적용하고, 1×1 컨볼루션으로 채널 수를 줄여 파라미터 효율을 높임
- 기여: 깊은 네트워크를 상대적으로 적은 파라미터로 구현하는 새로운 패러다임을 제시5
4.4. ResNet (2015)
- 특징: 스킵 연결(Skip Connection)을 도입한 잔차 학습(Residual Learning) 구조
- 기여: 50층 이상의 매우 깊은 네트워크 학습을 가능케 하여 ImageNet 등 대규모 대회에서 우수한 성능 달성6
4.5. DenseNet (2017)
- 특징: 각 층이 이전 모든 층의 출력을 입력으로 사용하는 특징 재사용(Feature Reuse) 구조
- 기여: 파라미터 효율이 좋으며, 데이터가 적은 환경에서도 높은 성능을 보임7
4.6. EfficientNet (2019)
- 특징: 너비(Width), 깊이(Depth), 해상도(Resolution)를 균형 있게 스케일업하는 컴파운드 계수(Compound Coefficient) 전략
- 기여: 적은 파라미터로 높은 정확도와 빠른 추론 속도를 동시에 달성8
5. CNN의 주요 응용 분야
5.1. 이미지 분류 (Image Classification)
CNN은 이미지 내 객체나 장면을 분류하는 데 탁월한 성능을 보입니다.
- 응용 사례: 스마트폰 자동 태깅, 웹 이미지 자동 분류, 의료 영상 진단 등
5.2. 객체 탐지 (Object Detection)
이미지 안에서 여러 객체의 위치와 종류를 동시에 알아내는 문제입니다.
- 응용 사례: 자율주행차(Autonomous Vehicle)에서 보행자 검출, CCTV(Closed-Circuit Television) 영상 분석, 실시간 객체 탐지(YOLO(You Only Look Once) 계열)9
5.3. 의료 영상 분석 (Medical Imaging)
CT, MRI, X-ray 등 다양한 의료 영상에서 질병을 진단하거나 병변을 분할(Segmentation)합니다.
- 응용 사례: 망막 이미지 기반 당뇨병성 망막병증 진단, 피부 병변 분류 등
5.4. 자율주행 및 운전자 보조 (Autonomous Driving & ADAS)
도로 상황에서 차선, 신호등, 보행자 등 다양한 객체를 인식하여 주행 의사결정(Decision-Making)에 활용합니다.
- 응용 사례: 자율주행차의 시각 인지, 도로 주행환경 분석
6. CNN의 한계점 및 극복 방법
6.1. 과적합 (Overfitting)
- 문제점: 수백만 개의 파라미터를 가진 심층 모델은 학습 데이터에 지나치게 맞춰질 가능성이 높음
- 해결법:
- 드롭아웃(Dropout): 학습 시 무작위로 일부 뉴런을 비활성화
- L2 정규화(Regularization), 얼리 스토핑(Early Stopping)
- 전이 학습(Transfer Learning): 대규모 데이터로 사전 학습된 모델 활용
6.2. 내부 공변량 변화 (Internal Covariate Shift)와 훈련 어려움
- 문제점: 네트워크가 깊어질수록 각 층의 입력 분포가 계속 변해 학습을 어렵게 만듦
- 해결법:
- 배치 정규화(Batch Normalization): 미니배치 단위로 정규화하여 학습 안정화
- 가중치 초기화(Weight Initialization): Xavier/He Initialization 등 적절한 초기화를 활용
6.3. 데이터 부족과 일반화 (Generalization) 문제
- 문제점: 대량의 라벨 데이터를 확보하기 어려우면 모델의 일반화 성능이 저하됨
- 해결법:
- 데이터 증강(Data Augmentation): 회전, 이동, 크롭 등을 통해 학습용 이미지를 다양화
- 자기 지도학습(Self-Supervised Learning): 라벨 없이도 유의미한 표현을 학습해 소량의 라벨로도 고성능 달성
6.4. 기타 한계
- CNN은 회전(Rotation), 스케일 변화(Scale Variation)에 대한 완벽한 불변성을 보장하지 않음
- 설명 가능성(Explainability) 측면에서 한계가 있어, Grad-CAM(Gradient-weighted Class Activation Mapping) 등 해석 기법을 통한 보완 연구가 활발히 진행 중
7. CNN과 다른 딥러닝 모델과의 비교
7.1. CNN vs RNN (Recurrent Neural Network)
- RNN: 순차적 데이터(문장, 음성 등)의 시간적 의존성(Temporal Dependency) 학습에 특화
- CNN: 이미지처럼 공간적(Spatial) 특징을 추출하는 데 최적화, 병렬 연산이 용이
7.2. CNN vs Transformer
- Transformer: Self-Attention으로 전역적(Global) 관계를 학습하며 병렬 연산에 강점
- CNN: 지역적(Local) 특징 추출에 능하며, 주로 시각적 데이터를 효율적으로 처리
- 최근에는 두 접근법을 결합한 하이브리드 모델(Hybrid Model)들이 제안되고 있음
7.3. 기타 비교
- 완전연결 신경망(MLP, Multi-Layer Perceptron)에 비해 CNN은 국소 연결(Local Connectivity) 및 가중치 공유를 통해 파라미터 수를 크게 줄이고, 효율적인 학습을 수행함
8. CNN의 최신 연구 동향
8.1. 새로운 모델 및 하이브리드 접근
- Vision Transformer (ViT): 이미지를 패치 단위로 처리하는 순수 Transformer 구조로, 최신(State-of-the-art) 성능을 달성10
- 하이브리드 모델(Hybrid Model): CNN과 Transformer의 장점을 결합한 ConvNeXt, Resformer 등
8.2. 효율적 모델 설계 및 경량화
- 경량(Lightweight) 모델: MobileNet, EfficientNet 시리즈 등을 통해 모바일 및 임베디드 환경에서 활용 가능
- 모델 압축(Model Compression): 프루닝(Pruning), 지식 증류(Knowledge Distillation), 양자화(Quantization) 등을 통해 연산량과 메모리를 절감118
8.3. 자기 지도학습(Self-Supervised Learning) 및 표현 학습(Representation Learning)
- 대조 학습(Contrastive Learning): SimCLR, MoCo 등 라벨이 없는 데이터로도 유의미한 특징 학습
- 라벨링 비용 절감 및 소량의 라벨로도 높은 성능을 달성할 수 있어 각광받는 분야
8.4. 설명 가능성(Explainability)과 해석
- Grad-CAM 등 시각화 기법을 통해 CNN이 어떤 부분에 주목하는지 설명(Explain) 가능하도록 연구
- 특히 의료 영상 등 신뢰도가 중요한 분야에서 활발히 사용
참고문헌
-
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278–2324. ↩ ↩2
-
ZHANG, Aston, et al. (2021). Dive into deep learning. arXiv preprint arXiv:2106.11342. ↩ ↩2
-
Krizhevsky, A., Sutskever, I., & Hinton, G.E. (2012). ImageNet classification with deep convolutional neural networks. NeurIPS, 1097–1105. ↩ ↩2
-
Simonyan, K., & Zisserman, A. (2015). Very Deep Convolutional Networks for Large-Scale Image Recognition. ICLR 2015 (arXiv:1409.1556). ↩ ↩2
-
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., … Rabinovich, A. (2015). Going Deeper with Convolutions. CVPR, 1–9. ↩ ↩2
-
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recognition. CVPR, 770–778. ↩ ↩2
-
Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K.Q. (2017). Densely Connected Convolutional Networks. CVPR, 2261–2269. ↩
-
Tan, M., & Le, Q.V. (2019). EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. ICML, 6105–6114. ↩ ↩2
-
Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. CVPR, 580–587. ↩
-
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., et al. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ICLR 2021 (arXiv:2010.11929). ↩
-
Howard, A.G., Zhu, M., Chen, B., Kalenichenko, D., et al. (2017). MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv:1704.04861. ↩